
A data lakehouse is a modern data architecture that blends the scalability, flexibility, and low cost of data lakes with the performance, governance, and reliability of data warehouses.
It allows organisations to store and analyze all types of data—structured and unstructured—while maintaining strong management and analytics capabilities.
Key Features of a Data Lakehouse:
- Supports all file types: Stores everything from traditional transaction data (CSV, Parquet, Avro) to images, videos, and text (PNG, MP4, TXT).
- Vendor flexibility: Uses open-source file formats like Apache Parquet, Iceberg, and ORC, enabling seamless integration with tools like Spark and access via SQL, Python, Scala, or R.
- Data quality: Enforces schemas and validation rules to ensure consistency and accuracy.
- Data governance: Provides access controls, lineage tracking, metadata management, and audit trails for transparency and compliance.
- Independent scaling: Decouples storage and compute, allowing flexible scaling and cost control.
- BI and real-time reporting: Direct access for BI tools eliminates the need for duplicated datasets.
- Real-time analytics: Supports streaming data for instant insights.
- AI readiness: Unifies diverse data types, supports dynamic compute resources, and enforces enterprise-grade security for AI initiatives.
- Reliability with ACID transactions: Ensures atomicity, consistency, isolation, and durability for trustworthy data management.
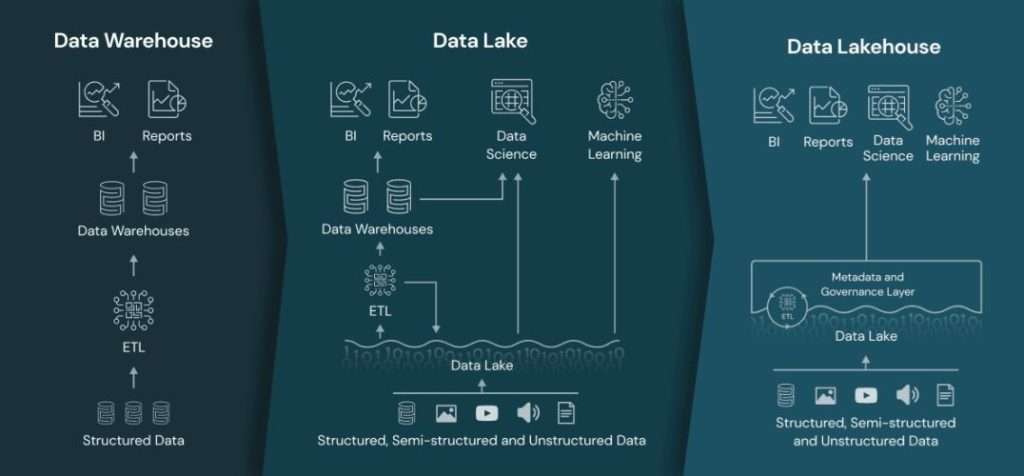
How a Data Lakehouse Differs from a Data Warehouse or Data Lake:
A data lakehouse combines the best of both worlds. Unlike a traditional data warehouse, it can store raw, unstructured data affordably. Unlike a data lake, it provides reliable data management, making analysis and queries faster, easier, and more accurate.
Every day, the world generates over 400 million terabytes of data, and most businesses are still playing catch-up. Legacy warehouses buckle under the pressure, and pure data lakes can’t provide the structure needed for fast analytics.
A data lakehouse combines the low-cost storage of data lakes with the structured querying of data warehouses. It is typically built on open table formats like Delta Lake, Apache Iceberg, and Hudi. However, behind every high-performing data lakehouse are two crucial decisions:
- Which columnar format to use
- How and when to cache data
These choices impact latency, cost, and even data freshness. This article will cover:
- When each format works best
- Which cache layers help, and when do they hurt
- Lessons from real-world architectures
- How ClicData supports hybrid data lakehouse stacks
Understanding Columnar Formats
So why use columnar data formats in data lakehouses?
Unlike row-based formats like CSV or JSON, which store all fields of a record together, columnar formats group values by column on disk. This structure makes analytical queries much faster, since engines can read only the needed columns instead of scanning entire rows.
When running queries like SELECT region, revenue FROM sales, a columnar engine only reads the region and revenue columns, not the entire row. This reduces I/O and improves cache performance.
Columnar Format Comparison
| Format | Use Case | Compression | Performance | Update/Delete | Compatibility | Users |
|---|---|---|---|---|---|---|
| Parquet | General-purpose (batch & stream) | Snappy, ZSTD, dictionary | High (columnar scans) | Limited native; extended by Delta/Iceberg | Spark, Trino, Presto, Hive, Flink | Netflix, Uber, Databricks |
| ORC | Hive-native (Hadoop, Tez) | Indexing, bloom filters | Optimized for Hive vectorization | Limited; best in Hive systems | Hadoop ecosystem | LinkedIn, Facebook (legacy) |
| Arrow | In-memory analytics | N/A (in-memory) | Real-time, zero-copy | N/A (not for storage) | DuckDB, DataFusion, Apache Flight | InfluxDB, Snowflake (internal) |
How to Choose the Right Data Format
Picking the right format depends on several factors:
Ecosystem Compatibility
Your format must match your compute engine. Delta Lake is built on Parquet and works best in Spark environments. If you are on Hadoop, ORC might be better. Arrow is best for real-time in-memory systems.
Read/Write Patterns
For read-heavy and append-only datasets, e.g., logs and metrics, Parquet offers efficient scanning. It is not designed for frequent updates. If your data changes often, use formats like Delta or Iceberg, which support ACID operations and compact small files automatically.
Recent versions of Delta Lake also support Iceberg-compatible APIs, enabling broader compatibility across engines like Trino, Flink, and Dremio. This trend toward API convergence is reducing vendor lock-in and improving format portability.
Latency and Concurrency Needs
Arrow is built for in-memory processing, offering fast reads and low latency for interactive applications. It supports high concurrency without file I/O overhead. Parquet and ORC are disk-based and perform best in batch or scheduled workloads, especially when backed by caching layers.
Schema Evolution
Iceberg and Delta support evolving schemas with version control, type promotion, and column renames. This is important for long-lived pipelines or streaming data. ORC supports basic schema evolution but lacks flexibility. Arrow is schema-fixed at runtime and does not support persistent schema changes.
The data lakehouse ecosystem is moving toward a common API layer, where engines can work with Delta, Iceberg, or Hudi via shared interfaces. Tools like Apache XTable and project UniForm (by Databricks) aim to make table format boundaries invisible to end users, accelerating lakehouse adoption.
How Cache Layers Stack in a Data Lakehouse
In a data lakehouse, data is often stored in cloud object storage like S3, Azure Data Lake, or Google Cloud Storage (GCS). These systems are cheap but have high read latency. Every query that scans files from remote storage adds delay and cost.
Caching can help solve this by storing frequently accessed data or metadata closer to compute. It reduces object store access and enhances performance for interactive dashboards and exploratory queries.
For example, Databricks reports up to 5x faster performance on real-world workloads, with Photon cache playing a major role in accelerating repeated queries. Similarly, Uber’s Hudi uses metadata indexing and caching to support incremental reads.
Key Cache Types in Lakehouses
Here are the main cache types in data lakehouses:
- Metadata Caches: Engines like Spark or Presto cache schema and partition data to avoid slow storage listing.
- Data Skipping Indexes: Formats like Delta or Hudi use min/max stats and clustering (e.g., Z-Ordering) to skip irrelevant files.
- Distributed Cache Layers: Tools like Alluxio keep hot data close to compute, while Photon adds vectorized caching at the execution layer. RAPIDS accelerates GPU-based reads and processing.
- In-Memory Caches: Spark and Flink let you pin DataFrames in memory for iterative ML, streaming, or ETL workloads.
Each type has strengths and tradeoffs, which makes it important to stack them properly in a data lakehouse architecture.
Cache Types Overview
| Cache Type | Layer | Best For | Pros | Limits |
|---|---|---|---|---|
| Metadata Cache | Metadata Layer | Query planning, schema lookups | Lightweight, avoids repeated file listings | No actual data caching |
| Data Skipping Indexes | Metadata + Execution | Partitioned/structured queries | Reduces I/O, faster scans | Needs well-designed partitions |
| Alluxio / Photon | Between storage & compute | Repeated queries on large datasets | Avoids S3 latency, boosts throughput | Requires memory/SSDs, added cost |
| RAPIDS | Compute (GPU) | High-speed analytics, ML pipelines | GPU-accelerated, optional file cache | Not a dedicated cache layer |
| Spark/Flink Cache | Compute Layer | ML training, iterative ETL | In-memory speed, easy to use | Temporary, volatile |
Choosing the Right Strategy
There is no universal lakehouse setup. Choosing the right combination of format and cache strategy depends on your workload, latency needs, cost limits, and storage architecture. Below are real-world scenarios to guide those choices.
1. Cold Storage + Cache for Cost Efficiency
For large datasets that rarely change, storing data as Parquet in S3 or ADLS and layering a cache like Alluxio or Databricks Photon provides efficient and low-cost access.
ClicData enhances this setup by connecting both directly to Parquet files and to structured outputs such as views or tables in Databricks or Snowflake. This flexibility means teams can work with raw files when needed or tap into curated datasets for faster analysis. It enhances these connections by providing features like real-time data refreshes, schema versioning to manage structural changes, and dashboard caching, which collectively accelerate query performance and reduce infrastructure costs.
This setup enables business teams to analyze both current and historical data directly through dashboards without requiring complex ETL pipelines, making analytics more accessible and actionable.
2. Hot Analytics in Warehouse, Lake for Archive
In a hybrid setup, companies often load the most recent data from the last 30 to 60 days into a high-performance data warehouse such as Snowflake, BigQuery, or Redshift. This ensures that dashboards and reporting tools run quickly on the freshest metrics. Meanwhile, older data is left in the data lake in formats like Parquet or ORC, with metadata indexing and partition pruning making it efficient to query when needed.
ClicData’s platform is designed to handle this hybrid model seamlessly. You can use its 500+ connectors to pull fresh metrics from your data warehouse and simultaneously connect to your data lake to access historical logs. This allows you to centralize both layers in a single platform and balance speed for recent data with low-cost storage for compliance or archival needs. It also helps with performing unified analysis across both datasets without complex external references.
3. Hybrid Reads with Format-Aware Engines
For more complex data environments, many organizations skip the warehouse handoff and instead query their lake directly using engines that understand modern table formats like Delta Lake, Apache Iceberg, or Hudi. These engines support features such as transactions, time travel, and snapshot isolation at scale, while metadata caching and in-memory acceleration help close the performance gap with warehouses.
Netflix Case Study
Netflix is a well-known example. It manages petabyte-scale datasets with Apache Iceberg, which allows the company to run thousands of concurrent queries across its data lake without bottlenecks. Features like snapshot reads and time travel ensure analysts can work across historical and current datasets seamlessly, while compute remains decoupled from storage.
Decision Framework
Use the table below to choose the right combination of format and caching based on your technical needs:
| Workload | Latency | Freshness | Format | Cache | Best For |
|---|---|---|---|---|---|
| Archival / Audit Logs | Low | Low (append-only) | Parquet | Alluxio / None | Compliance, offline queries |
| BI Dashboards (Daily) | Medium | Medium | Parquet + Delta | Metadata + Spark cache | Internal reports, marketing dashboards |
| Interactive Analytics | High | High | Delta / Iceberg | Photon / RAPIDS | Clickstream, personalization, live apps |
| ML Pipelines (Iterative) | High | Medium | Parquet / Arrow | Spark / Flink in-memory | Feature generation, model training |
| Mixed / Federated Queries | Med–High | Variable | Iceberg / Delta | Alluxio + Data Skipping | Cross-team analytics with cost control |
Before selecting formats or cache layers, assess your system’s operational demands across these key areas:
- Query Latency: For fast dashboards or interactive queries, latency under one second is important. Use Photon with vectorized execution or Alluxio for in-memory caching.
- Cost Constraints: Avoid over-caching if query frequency is low. Reading Parquet files in batch mode directly from S3 or ADLS can cut costs. Caching adds speed but increases memory and compute spend, only worth it if queries repeat often.
- Data Freshness: For up-to-date metrics or real-time insights, use Delta Lake with Auto Loader and structured streaming. It supports incremental ingestion while keeping data queryable with low delay.
- Storage Scale: For petabyte-scale datasets, use Iceberg with hidden partitioning and metadata pruning. This reduces file scans and speeds up planning. Iceberg’s catalog integration also scales better for multi-engine environments.
Key Considerations for Implementation
Building an effective data lakehouse requires careful planning. Your choices around format, caching, and tools will directly affect performance, cost, and maintenance.
1. Data Volume and Velocity
The size of your datasets and the rate at which they change should drive your decisions.
- High-volume, low-change data, e.g., historical logs, is best stored in columnar formats like Parquet or ORC with scheduled caching.
- High-velocity data like sensor streams or financial trades can require append-optimized formats like Apache Hudi, with near real-time ingestion and low-latency cache refresh.
Uber Case Study
To manage fast-changing trip data, Uber rebuilt its data pipelines using Apache Hudi. This allowed their teams to ingest new events quickly, apply updates efficiently, and process late-arriving data with minimal delay. As a result, they improved data accuracy and cut end-to-end processing time for real-time analytics.
Note: Avoid formats like raw JSON or CSV in high-throughput pipelines. These inflate storage, degrade query performance, and hinder scalability.
2. Query Patterns
Understand how your teams query the data:
- Batch queries can tolerate higher latency and benefit from cheaper storage without aggressive caching.
- Interactive dashboards require sub-second latency and need cache layers or materialized views.
- Streaming use cases need incremental ingestion and fast write support, which traditional columnar formats struggle to handle.
Rovio Case Study
Rovio, the mobile game company behind Angry Birds, needed fast, interactive dashboards for their internal game services platform. Analysts required sub-second response times to explore gameplay and revenue metrics. They used Apache Druid for real-time ingestion, Spark for heavy transformations, and a time-series-optimized, in-memory layout to support live decision-making across teams.
3. Cost Implications
Each layer adds cost:
| Component | Cost Type |
|---|---|
| Data Lake (e.g., S3) | Low storage, high read latency |
| Caching Layer | High memory or SSD cost |
| Warehouse (e.g., Snowflake) | High compute, fast performance |
Trade-off: Caching improves speed but increases memory/storage use. Running queries directly on the lake reduces compute cost but adds latency. A hybrid model often balances the two.
4. Operational Complexity
Managing formats, caches, and freshness can increase overhead:
- File compaction and partitioning strategies vary between ORC, Parquet, and Hudi.
- Cache invalidation must be tied to data changes to avoid stale results.
- Schema evolution can break dashboards if not managed with rollback or versioning.
Tip: Use platforms like Delta Lake or Iceberg that support ACID guarantees, schema evolution, and metadata tracking to reduce risk.
5. Tooling and Ecosystem
Each data lakehouse framework handles formats, caching, and schema evolution differently. Here is how leading platforms compare:
| Platform | Format Support | Caching Support | Schema Management | Real-time Support |
|---|---|---|---|---|
| Delta Lake | Parquet | Yes (Databricks Cache) | Strong (Time Travel) | Good (via Spark Structured Streaming) |
| Iceberg | Parquet, ORC | Medium (custom setup) | Strong (Snapshot-based) | Excellent (Flink, Spark) |
| Hudi | Avro, Parquet | Built-in (RO Table caching) | Moderate (instant vs. merge-on-read) | Native (DeltaStreamer, Flink) |
| ClicData | Structured, Semi-Structured, Unstructured (via SQL + File-based Lake) | Yes (Caching + Materialization Engine) | Visual + Scripted Schema Controls | Yes (API Hooks, Scheduled Sync, Real-time Dashboards) |
Final Thoughts
Columnar formats and cache layers play different but complementary roles in modern lakehouse architectures. Columnar formats like Parquet, Delta, and Iceberg optimize storage and retrieval by reducing I/O and enabling efficient column pruning. Cache layers, whether in-memory, SSD-backed, or metadata-based, accelerate repeated queries and minimize latency for interactive workloads.
A solid data lakehouse setup doesn’t lean on just one tool. It blends the right formats and caching methods to match how the data is used. With newer tech like Photon, Iceberg v2, and vectorized engines, performance keeps improving, and so does the need to make smart choices.









